The OSTrails consortium held its General Assembly on 23-24 March in Braga, bringing together partners to review progress and align on the next phase of the project. The meeting marked a clear transition from framework development towards initial implementation across pilots
Discussions covered project results, pilot activities, technical readiness and capacity-building efforts, all framed within the broader objective of supporting interoperable and FAIR research practices across Europe.
Key Outcomes
The meeting confirmed that OSTrails is delivering tangible results that are actively used by the 41 partner organisations, highlighting the real-world impact, usefulness, and value of the outputs generated. The emphasis is now on supporting pilots in adopting and integrating the project’s outputs within their communities, ensuring that these are tested, validated, and effectively used in their diverse settings.

A strong position of the project at the European Open Science Cloud (EOSC) Federation was also highlighted during the discussions. OSTrails interoperability frameworks are already being adopted by several EOSC Nodes (e.g. PaNOSC, CSC – IT Center for Science Ltd) as important components for enabling Federation capabilities for planning, tracking and assessing knowledge production. In this context, long-term sustainability remains a key priority, with continued development and consolidation of OSTrails Commons, and the importance of governance approaches supported by community endorsement.
Year 2 has delivered a substantial set of results across the project’s core areas. In the FAIR domain, the project has developed and released multiple frameworks and services, supported by FAIR metrics and the publication of FAIR-related resources on platforms such as GitHub. Seven services have already adopted FAIR-IF components, with five partners actively using DCAT application profiles and one external platform having migrated to the framework.
In the DMP, work has progressed on machine-actionable Data Management Plans, including the development of application profiles, APIs, and alignment with RDA Common Standards. For scientific knowledge graphs, SKG-IF has been implemented across multiple infrastructures, including APIs and extensions. A validation and tagging framework have also been introduced, supported by an open-source graph-agnostic tool and a proposed registry of norms with persistent identifiers.
The project has also demonstrated strong outreach impact, reaching multiple stakeholders across Europe and beyond, with project outputs widely accessed through Zenodo.
A Look Back: What We Discussed
- PTA Pathways & Interoperability Reference Architecture
Participants emphasised that while the Findable, Accessible, Interoperable, Reusable – Interoperability Framework (FAIR-IF), Data Management Plan – Interoperability Framework (DMP-IF), and Scientific Knowledge Graph – Interoperability Framework (SKG-IF) are now well-developed, their real value will depend on how easily they can be applied in practice. Improving usability and providing clearer, more concrete guidance for pilot implementations were identified as essential next steps to ensure these frameworks effectively support reuse, standardisation, and system integration.

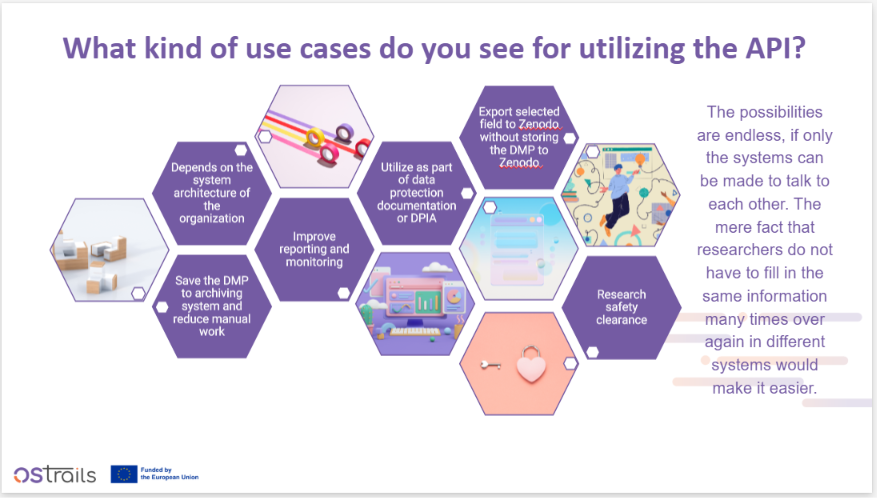
Building on this, discussions focused on advancing interoperability through concrete implementation efforts across pilots and services, where integration is already underway to combine FAIR assessment, machine-actionable DMPs, and SKG technologies into operational workflows. For example, DMP tools are being connected via APIs to enable automated creation and updating of plans, FAIR assessment services are being embedded into metadata harvesting pipelines, and SKG components are being used to link datasets, publications, and services within research infrastructures.
Several concrete tools and services were highlighted throughout the sessions. These include FAIRassist, used for the creation and discovery of FAIR metrics and benchmarks, FAIR Champion, which currently include two registered tests that serve as the first validation tools, and the broader FAIR metrics ecosystem, which now comprises 85 active metrics. In the DMP domain, tools such as DSW and ARGOS are being updated to support the DMP Common Standards, including API-based workflows and integration of the DMP Evaluator as a service. For scientific knowledge graphs, infrastructures such as ROHub, OpenAIRE, CESSDA, CLARIN, and OpenCitations are already implementing SKG-IF components and APIs.
At the same time, these discussions highlighted opportunities to further strengthen the solutions being developed. Ongoing efforts are focusing on enhancing usability, improving metadata quality through more robust harvesting and validation approaches, and refining how technical concepts are translated into clear, user-facing guidance, key steps to support broader adoption and more effective use across diverse research communities.

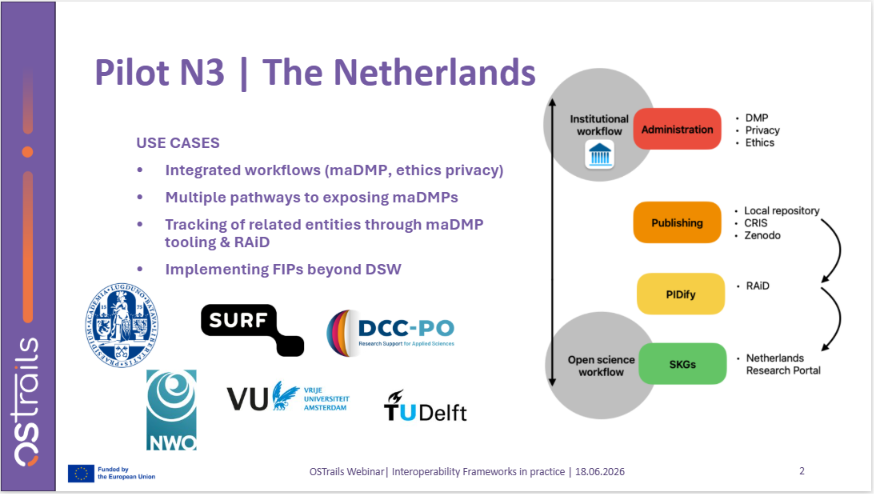
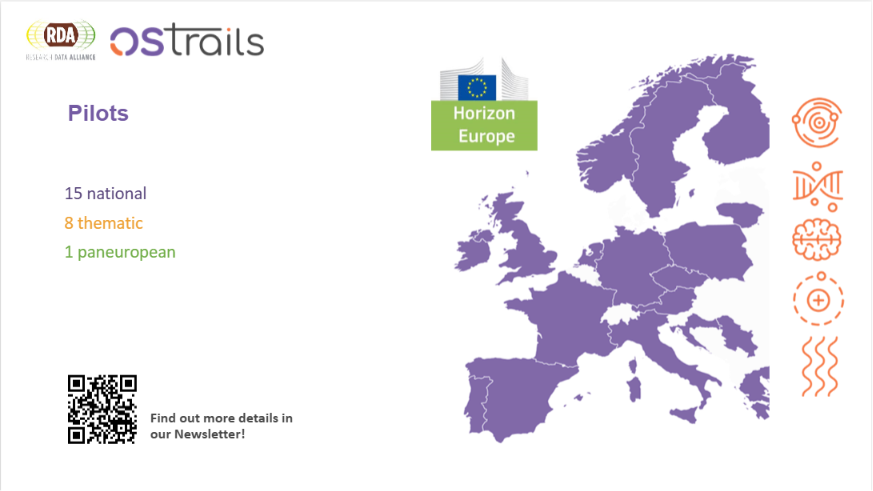
National pilots, such as those in Poland, Finland, Spain, and Sweden, are focusing on large-scale coordination across institutions, repositories, CRIS systems, and national infrastructures. For instance, the Spanish pilot now aggregates metadata from 191 repositories and has implemented validation mechanisms and controlled vocabularies for DMP, resulting in nationwide DMP publication coverage. The Finnish pilot is developing a national maDMP template designed to be applicable across approximately 60 organisations.
In parallel, thematic pilots, including Marine and Coastal Science, Social Sciences and Humanities, and Astronomy, are integrating OSTrails components directly into disciplinary workflows. These include the use of SKG editors, DMP APIs, FAIR assessment tools, and knowledge graph infrastructures to support research processes, metadata enrichment, and data publication pipelines.


Capacity Building
Capacity building is a central component of OSTrails, designed to support adoption, knowledge transfer, and long-term sustainability of project results (https://ostrails.eu/training).
The project is to develop a structured set of activities that include a training library, online courses, factsheets, a train-the-trainer bootcamp, and a mentorship programme. The training library serves as a central repository for reusable materials, while online courses focus on practical topics such as DMPs and machine-actionable workflows. Additional materials will be produced including how-to guides that provide structured and targeted information on how to use the OSTrails software, tools and services.
Immediately following the meeting, OSTrails delivered its first Train-the-Trainer Bootcamp on 25 March in Braga, marking an important step as the project moves into its implementation phase. The Bootcamp focused on equipping organisations, trainers, and pilot partners to act as multipliers, supporting wider adoption of OSTrails results.
Across all these activities, sustainability is a key consideration. Materials are being made available through existing infrastructures to ensure that capacity-building efforts are practical, accessible, and aligned with the needs of pilots and stakeholders.
Conclusions
The General Assembly confirmed that OSTrails is now firmly in its implementation phase, with strong foundations in place across FAIR, DMP, and SKG interoperability frameworks. The immediate focus is on supporting pilot implementations while advancing upcoming deliverables and milestones.
Work will continue implementing APIs and strengthening interoperability, alongside hands-on support for pilots adopting OSTrails tools and services. Ensuring that these solutions are practical, well-documented, and effectively integrated into real-world environments will be a shared priority across partners.
Capacity-building efforts will expand through training courses, bootcamps, and supporting materials, helping communities adopt and apply the project’s outputs. At the same time, attention to user support and long-term sustainability will remain central to maximising impact.
By aligning technical development with community engagement and structured support, OSTrails is well positioned to contribute to a more interoperable and FAIR-aligned research ecosystem.
The General Assembly also provided a valuable opportunity for partners to meet in person, exchange ideas, and strengthen collaboration across the consortium. Bringing the team together reinforces the shared commitment to the project’s goals and supports the collective effort to promote OSTrails solutions and maximise their impact across the research ecosystem.